Quick takeaway
Dead clicks are clicks with no visible response, rage clicks are repeated rapid clicks that suggest frustration. In PLG SaaS, both matter most when they cluster on activation-critical steps. Use session replay to confirm whether it’s a broken interaction, slow feedback, or an analytics artifact, then prioritize fixes by segment impact and downstream activation lift.
If your PLG signup or onboarding metrics look fine but activation is flat, these two signals are often the missing “why”. Use session replay for context and prioritize what matters most for PLG activation.
Table of contents
- Problem signals that usually show up first
- Key definitions (and the one nuance most teams miss)
- Rage clicks vs dead clicks: a decision framework (with edge cases)
- Symptom-to-cause map: what each signal usually means
- The 6-step triage workflow (built for activation)
- How to prioritize fixes for PLG activation rate
- How to measure outcomes after you ship
- Common follow-up questions
- Related answers
Problem signals that usually show up first
In PLG SaaS, you rarely hear “rage clicks” in a ticket. You hear: “The button does nothing.” “Invite flow feels broken.” “I got stuck at verification.” The metric version is often: stable signup volume, worse step completion inside onboarding, then flat activation.
A useful mental model: dead clicks often show up at the first moment your UI fails to acknowledge intent, rage clicks show up when a user tries to brute-force past that failure. Use session replay to validate what actually happened, and keep the work anchored to activation-critical steps.
Key definitions (and the one nuance most teams miss)
- Rage clicks: repeated rapid clicks in the same area, typically signaling frustration or confusion.
- Dead clicks: clicks that produce no visible response (no navigation, no state change, no feedback).
- Error clicks: clicks that lead to an error state (front-end error, validation error, failed request).
- Frustration signals: behavioral patterns that correlate with “something is wrong” moments.
- Activation-critical step: any step that reliably predicts activation (not just signup), like first invite sent, first integration connected, first project created.
The nuance most teams miss: one user can generate both signals in one moment. A dead click can be the trigger, rage clicks can be the escalation.
Rage clicks vs dead clicks: a decision framework (with edge cases)
Use this framework to label the signal correctly before you prioritize it.
1) What did the UI do after the first click?
- Nothing changed: start by treating it as a dead click.
- Something changed, but slowly: treat it as slow feedback, which can create rage clicks that look like UX bugs.
- Something changed, but not what the user expected: treat it as misleading affordance.
2) Where is it happening in the journey?
- Activation-critical step (invite, integration, first key action): escalate severity by default.
- Non-critical exploration: investigate, but don’t steal cycles from activation.
3) Is it clustered or isolated?
A single occurrence might be a mis-tap or impatience. A hotspot cluster usually means a real UX/performance issue or a repeated instrumentation pattern.
Edge cases (common false positives)
- Habitual double-clicking on desktop
- Slow network/device making normal users look “angry”
- Disabled states that still look clickable
- Overlays intercepting clicks (cookie banners, modals)
- Tracking mismatch between click events and UI outcomes
Symptom-to-cause map: what each signal usually means
| What you see | Likely cause | How to verify fast | Typical fix |
|---|---|---|---|
| Dead clicks on primary CTA (same element) | Broken handler, overlay intercept, disabled state | Watch sessions, check click target + element state | Fix click binding, adjust overlay, clarify disabled state |
| Rage clicks after a spinner appears | Latency or unacknowledged loading | Look for slow API response or long wait | Add immediate feedback, optimistic UI, speed up endpoint |
| Dead clicks concentrated on mobile | Tap target too small, sticky elements blocking | Segment by device, compare tap area vs UI | Increase hit area, adjust layout, remove blockers |
| Rage clicks on “Next” in a form step | Validation friction with unclear errors | Repeated submits + error state in replay | Inline validation, clearer error copy, preserve input |
| Dead clicks on nav items | Routing bug, blocked by auth/feature flag | Navigation intent vs resulting state | Fix routing, tighten flag logic, add fallback states |
| Rage clicks on “Connect integration” | OAuth popup blocked, third-party step confusion | Replay shows popup blocked or context switch | Detect blockers, add instruction, retry/continue states |
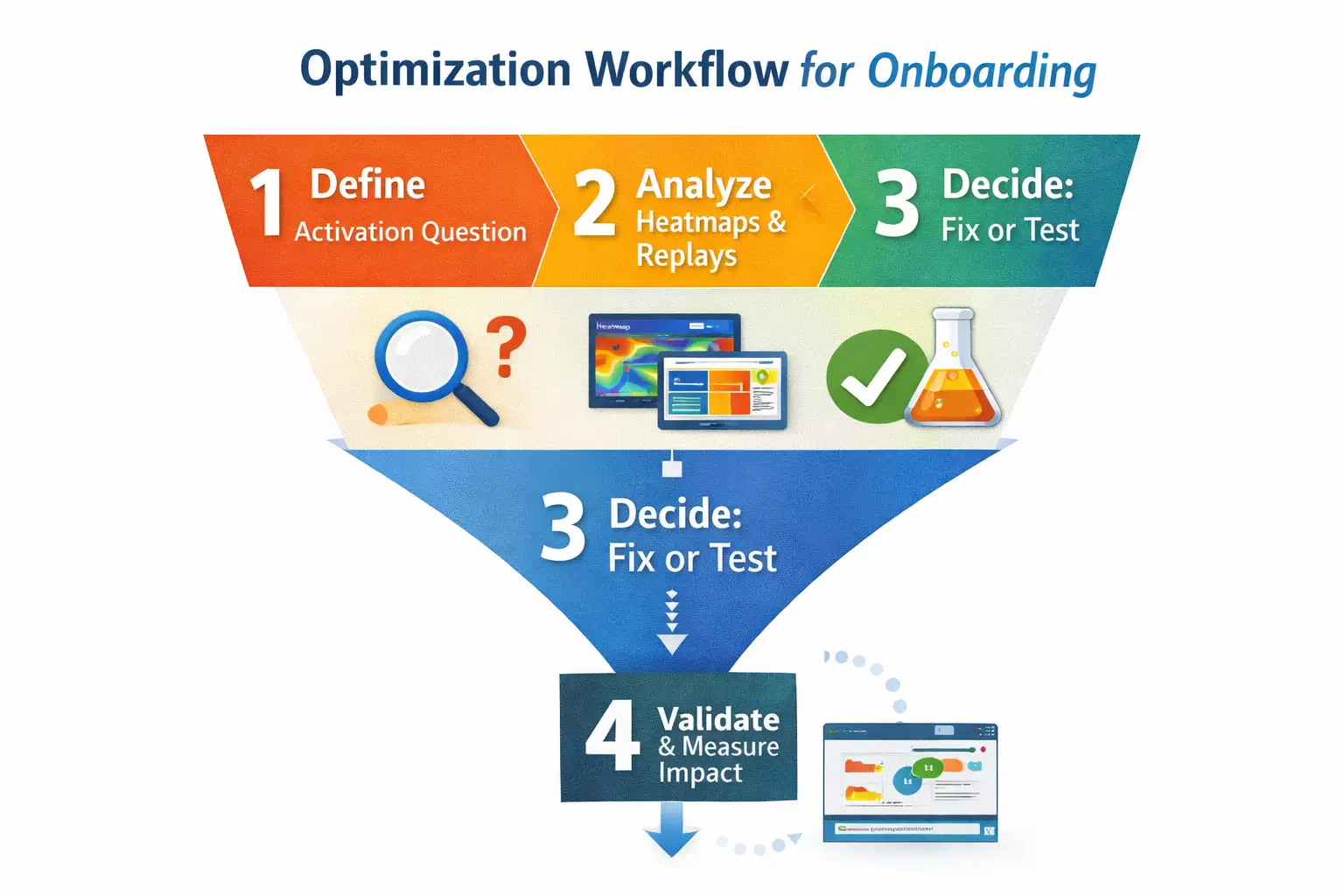
The 6-step triage workflow (built for activation)
This workflow reduces false positives and gets you to the fix that can move activation.
- Pick the activation-critical slice: Choose one onboarding path that correlates with activation and anchor it to your PLG activation funnel.
- Find clustered hotspots: Look for repeated patterns on the same step, element, or segment.
- Watch the sessions behind the cluster: Use session replay to confirm what the user experienced.
- Classify the root cause: UX/affordance, performance/latency, technical failure, or measurement artifact.
- Estimate impact on activation: Prioritize blockers that cluster on steps before activation and align with drop-off.
- Ship the smallest trust-restoring fix: Feedback states, clearer validation, removing intercepting overlays, or fixing failures.
How to prioritize fixes for PLG activation rate
When everything looks like a UX bug, your roadmap becomes noise. Use a simple rubric: journey criticality, blocker severity, cluster strength, segment concentration, and downstream correlation with activation. Hotspots that are on the activation path and block progress should win, even if raw volume is lower.
Keep the work anchored to PLG activation, and validate the experience end-to-end using session replay.
How to measure outcomes after you ship
- Activation rate (primary)
- Step completion rate on the affected step
- Drop-off rate immediately after the affected step
- Error rate (if technical)
- Support/contact rate (if you tag it)
If the frustration signal drops but completion does not improve, you likely hid the symptom without fixing the underlying friction. Re-check sessions in session replay and keep the prioritization aligned to activation outcomes.
Common follow-up questions
How many clicks count as a “rage click”?
There isn’t a single universal threshold. Treat it as a pattern: rapid repeat clicks in the same area that coincide with lack of feedback, delay, or confusion.
Can dead clicks be intentional?
Yes. Users sometimes click non-interactive text or icons to test clickability. If it clusters, it still signals an affordance problem.
Are rage clicks always a UX problem?
No. Rage clicks can be performance (slow feedback), technical failures (request fails), or measurement artifacts. Session context is the tie-breaker.
How do I detect dead clicks reliably?
Combine click activity with “no visible response” signals, like no navigation, no state change, or no downstream event. Connecting clicks to replay context reduces false positives.
Which matters more for activation: rage clicks or dead clicks?
Whichever occurs on an activation-critical step and blocks progress. Dead clicks often identify the initial failure, rage clicks often reveal where frustration peaks.
How do I avoid prioritizing false positives?
Don’t prioritize by click counts alone. Validate via session context, segment concentration, and whether the hotspot aligns with step drop-off toward activation.
Related answers
Next steps
Pick one activation-critical flow and identify the top cluster of dead clicks or rage clicks. Then validate root cause in session replay and ship the smallest fix that restores trust.

Roman Mohren is CEO of FullSession, a privacy-first UX analytics platform offering session replay, interactive heatmaps, conversion funnels, error insights, and in-app feedback. He directly leads Product, Sales, and Customer Success, owning the full customer journey from first touch to long-term outcomes. With 25+ years in B2B SaaS, spanning venture- and PE-backed startups, public software companies, and his own ventures, Roman has built and scaled revenue teams, designed go-to-market systems, and led organizations through every growth stage from first dollar to eight-figure ARR. He writes from hands-on operator experience about UX diagnosis, conversion optimization, user onboarding, and turning behavioral data into measurable business impact.